
Comme vous l'avez probablement remarqué, Dall-E 3 a récemment fait son apparition directement dans ChatGPT. C'est donc l'occasion pour moi de partager avec vous mes premières impressions après une semaine d'utilisation...
Dall-E 3: c'est quoi au juste?
Dall-E 3 est une version avancée de l'IA de génération d'images développée par OpenAI. Cette technologie permet de transformer des descriptions textuelles en images visuelles de haute qualité. En d'autres termes, vous pouvez simplement écrire ce que vous souhaitez visualiser, et Dall-E 3 se charge de créer une image qui correspond à votre description. L'intégration de Dall-E 3 avec ChatGPT offre une toute nouvelle expérience pour l'utilisateur, permettant une transition fluide entre la narration textuelle et visuelle. Que vous soyez un créateur de contenu, un artiste ou simplement quelqu'un qui souhaite explorer les possibilités de l'IA, Dall-E 3 ouvre un tout nouveau monde de créativité et d'innovation.
Alors, ces premières impressions?
Après avoir généré un bon nombre d'images, surtout pour des raisons de tests, je peux en tirer les premières conclusions.
Tout d'abord, je dois vous dire que j'ai été vraiment saisi par la différence avec la version précédente. Plus de personnages à 3 jambes et d'autres anomalies qui rendait souvent les images inutilisables. Dall-E 3 en soi est déjà un énorme saut en avant. Et son association avec ChatGPT rend le résultat et l'utilisation encore plus bluffant. Certes, il y a encore des ratés... Mais qui aurait imaginé de tels résultats il y a 5 ans en arrière seulement?
Donc, je ne vais pas trop critiquer car, il faut l'avouer, c'est une percée majeure dans le domaine de la création. Mais je vais quand même mentionner quelques points où il y a encore du progrès à faire.
Dall-E 3 et ChatGPT: les grands pas en avant
Commençons par du positif...
Les "itérations"
Tout comme la création du contenu textuel, ChatGPT vous permet d'arriver au meilleur résultat par itérations - vous répétez la procédure jusqu'à l'obtention du résultat souhaité.
Une fois que Dall-E a généré les images, vous pouvez demander des ajustements directement à ChatGPT sans devoir réécrire les prompts. Certes, il n'est pas possible de modifier une image déjà généré (voir plus bas), ChatGPT va modifier les prompts en tenant compte de vos demandes précédentes et les modifier automatiquement.
Exemple: vous demandez à ChatGPT de créer "une image d'un chat qui dort dans un panier". Une fois l'images générés, vous vous direz: "ah, ce serait bien si le chat était noir". Plutôt que de réécrire toute votre demande, il suffit de dire à ChatGPT que le chat doit être noir. Il créera de nouveaux prompts automatiquement et générera de nouvelles images...
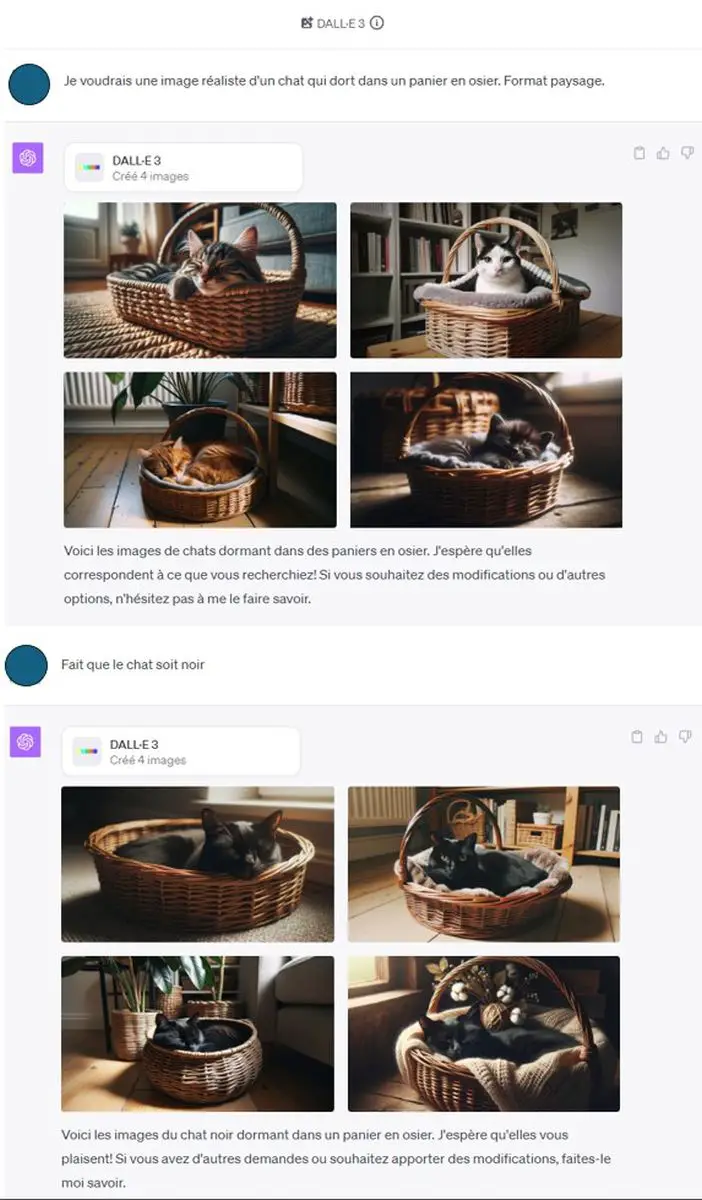
Enfin plus que des images carrés!
Contrairement à son prédécesseur et à d'autres outils de génération d'images par IA, Dall-E 3 vous permet enfin de générer les images dans 3 formats différents. En plus des habituels "carrés", vous pouvez maintenant générer des images en format "paysage" et en format "portrait".
Il suffit de demander... Dans votre prompt 🙂
Si vous écrivez vos prompts en français, vous pouvez utiliser les noms suivants. C'est officiellement confirmé, ces termes vont fonctionner:
- "Carré" pour le format carré (1024 x 1024)
- "Paysage" pour les images horizontales(1792 x 1024)
- "Portrait" pour les images verticales(1024 x 1792)



D'autres formats ou tailles ne sont, hélas, pas encore disponibles. Mais déjà l'ajout de deux formats les plus utilisés est un grand pas en avant.
Une nette diminution des anomalies
Une des évolutions les plus visibles est une (presque) disparition des anomalies qui étaient courantes dans la version précédente...
Tout le monde se souvient encore des humains à trois bras ou 6 doigts. Cela existe encore mais dans une bien moindre mesure.

Mais l'erreur est humaine... Ou plutôt artificielle 🙂

Votre imagination est la seule limite... (en plus du copyright)
Tout comme d'autres outils de génération de contenu, Dall-E peut créer à peu près tout ce que vous lui demandez... Cela dépend juste de votre imagination...
Vous souhaitez une "Tour Eiffel façon Van Gogh" ou une "bonne bière"... verte? Pas de problème!


Mais sachez que votre imagination sera, les droits d'auteur obligent, quelque peu bridée (voir le point "Double censure" plus bas). Mais avec un peu d'entrainement et des essai-erreurs, il est possible de s'en sortir assez honorablement.
Les textes dans les images - un net progrès dans Dall-E 3
Le gros problème de Dall-E 2 était son incapacité d'incorporer le texte dans l'image générée. Bonne nouvelle! Dans Dall-E 3, l'incorporation de texte se pas BEAUCOUP mieux. Un petit bémol - c'est plus simple avec des textes en anglais qu'avec des textes en français...
Et voici un exemple pour montrer que cela marche...

... mais pas toujours 🙂

Comme vous pouvez le constater, malgré les quelques quacks, les résultats sont tout de même époustouflants... En bas de cet article vous trouverez une galerie avec d'autres exemples.
Les Défis (restants) à relever pour Dall-E 3
Passons maintenant au points qui séparent encore Dall-E de la perfection...
La Persistence toujours la grande absente
Probablement la fonctionnalité qui brille encore le plus par son absence est, à mon humble avis, la persistance. Actuellement, Quand vous envoyez un prompt à Dall-E, ce dernier génère l'image à partir de zéro, en se basant uniquement sur votre prompt. Une fois l'image généré, il "l'oublie" directement. Si vous lui envoyez le même prompt à nouveau, vous aurez des résultats différents. Cela est dû à sa manière de fonctionner (voir ci-dessus) et à la composante "hasard" dans son modèle.
Ce comportement a de très grandes répercutions sur son utilisation pratique. Cela signifie, par exemple, que vous ne pouvez pas imaginer un personnage et demander à Dall-E de vous fournir les images de ce personnage dans des situations différentes. Plus votre description sera détaillée, plus le résultat des différents images sera proche. Mais il ne sera pas le même.
Vous aurez donc du mal à vous en servir pour illustrer votre livre par exemple. Et ceci peut être un grand problème pour certains.
Mais la résolution de ce problème est un défi de taille. Si vous souhaitez en savoir davantage, je vous propose l'aperçu de ce défi plus en détail ci-dessous.
Face à la "double censure"
Il est bien connu que OpenAI n'a pas lésiné sur les moyens en ce qui concerne la censure de ChatGPT. Que l'on soit d'accord ou pas avec une telle mesure, il s'agit d'un fait. Du côté de Dall-E, le même son de cloche: un bridage assez important.
En combinant ces deux outils, on obtient, nécessairement, une double censure: certaines de vos demandes ne passeront pas par ChatGPT, d'autres seront refusées lors de la génération des images par Dall-E.
D'un côté c'est compréhensible, de l'autre c'est parfois très frustrant... Oubliez donc tout ce qui touche à la violence, les images pour adultes, les images de personnes existantes, les "images dans le style d'un artiste particulier" (ici vous pouvez mentionner les artistes dont le dernier oeuvre date de plus de 100 ans)...
Et pour tout cela - c'est OpenAI / ChatGPT / Dall-E qui décident... S'ils décident qu'une demande est à l'encontre de leur règles, vous n'aurez pas votre image.
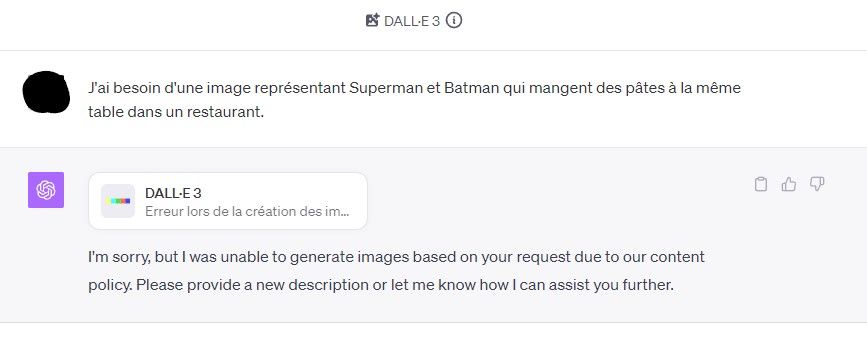
Pour vivre avec toutes ces règles, essayez de reformuler vos prompts de différentes manières. Parfois c'est une phrase ou une expression qui font que le système décide qu'il s'agit d'une violation des règles.
L'impossibilité de modifier une image existante
Si vous espériez pouvoir fournir à Dall-E une image et lui demander de la modifier, vous serez malheureusement déçus. Rien de tel n'est d'actualité pour le moment.
Et pour les raisons ci-dessous, cela ne risque malheureusement pas d'arriver de sitôt...
-
Architecture du modèle: Dall-E est conçu pour générer de nouvelles images à partir de textes d'invite, et non pour éditer ou modifier des images existantes. L'architecture du modèle n'est pas équipée pour prendre une image existante comme entrée et y apporter des modifications. Même si avec la reconnaissance d'image récemment ajouté à ChatGPT, il y a une lueur d'espoir de ce côté-là...
-
Données d'entraînement: Dall-E est formé sur un ensemble de données de paires texte-image, et non sur un ensemble de données qui inclut des modifications d'images existantes. Cela signifie que le modèle manque du "savoir-faire" nécessaire pour éditer des images.
-
Complexité computationnelle: Modifier une image existante tout en conservant son contexte et ses éléments originaux pourrait être coûteux en termes de calcul et complexe à mettre en œuvre.
-
Contraintes juridiques et (surtout) éthiques: Autoriser les modifications d'images existantes pourrait soulever des questions liées à la violation du droit d'auteur. N'oublions pas non plus que cela représenterait une port grande ouverte à toute sorte d'abus: les photomontages, les deepfake et j'en passe. On peut se demander si la société est vraiment prête et équipée à affronter une telle technologie?
Association avec ChatGPT - les principaux avantages
Dans tout les cas, le fait d'associer ChatGPT et Dall-E est une idée géniale pour l'utilisateur. Et cela pour plusieurs raisons. Voici la liste de celles qui m'ont le plus frappées...
- Gain de temps extraordinaire: Globalement, l'intégration de ces deux outils va vous faire gagner énormément de temps. Plus besoin d'écrire des requêtes sophistiquées en ayant exactement décrit ce que vous souhaitez (voir les points suivants). Idem pour les ajustements.
- Solution au manque de connaissances et d'inspiration: Si vous manquez d'inspiration, vous avez plusieurs possibilités d'obtenir tout de même un très bon résultat. Vous pouvez partir d'une idée de base et selon les créations de notre duo de choc, vous demandez des ajustements et des détails. Mais vous pouvez également demander directement à ChatGPT quelle serait la meilleure manière d'aborder le sujet. Et d'après sa réponse, vous envisagerez votre demande de création d'image. Un autre avantage - n'oubliez pas que ChatGPT reste ChatGPT. Et il connaît (presque) tout. Donc si vous souhaitez que l'image soit, par exemple, dans un style artistique particulier mais vous ne connaissez pas son nom, vous n'avez qu'à le décrire... ChatGPT trouvera lui même de quoi il s'agit et adaptera les s requêtes vers Dall-E en conséquence. Mine de rien, c'est très pratique!
- Les variations: Quand vous faites votre demande à ChatGPT, il la transforme lui même pour la transmettre à Dall-E. Mais contrairement à Dall-E disponible dans Bing.com/create ou d'autres outils, ce n'est pas un prompt qui est utilisé pour générer 4 images! ChatGPT génère, d'après votre instruction, 4 prompts différents qu'il transmet à Dall-E. Dall-E crée ensuite une image par prompt. Donc au final, vous avez toujours 4 images. Mais cette fois, en multipliant automatiquement des prompts, ChatGPT vous permet d'avoir une bien plus grand variation dans les résultats.
- Solution au problème de la langue: Ce n'est pas un secret, Dall-E comprend bien mieux l'anglais que le français (ou d'autres langues). Si vous n'êtes pas à l'aise avec l'anglais, ChatGPT arrive à votre rescousse! Il vous suffit de décrire en français ce que vous souhaitez comme image et ChatGPT le transforme en un prompt (en fait en 4) dans un anglais parfait. Qui donnera de bien meilleurs résultats une fois transmis à Dall-E.
- Coup de génie commercial: Cette association est un vrai coup de génie de la part de OpenAI et de Microsoft. Plutôt que d'avoir deux outils séparés, ils arrivent à créer une synergie en les combinant. La valeur ajoutée pour l'utilisateur est incontestable et va certainement faire grimper le nombre d'utilisateurs de ChatGPT. Et vous imaginez quand vous pourrez ajouter, grâce à ChatGPT et Dall-E, des images générés par IA directement dans vos présentations PowerPoint? Google a vraiment des soucis à se faire...
La galerie de Dall-E 3: pour un peu d'inspiration
Si vous voulez partager vos créations, n'hésitez pas! La catégorie Dall-E du FORUM ChatGPT-Malin est prévu pour cela!













